Crawling and Indexing: How Search Engines Find and Store Your Pages
Crawling and indexing are two of the most important ideas in SEO because they determine whether search engines can find your pages and consider them for rankings. If that process fails, strong content alone will not be enough.
This is why crawling and indexing deserve a dedicated place in any technical SEO cluster. Many sites publish useful pages but still underperform because important URLs are hard to discover, excluded from the index, or diluted by duplicate and low-value pages elsewhere on the site.
This article explains what crawling and indexing mean, why they matter, how the process works, what usually goes wrong, and how to approach the topic strategically. As a cluster page, it should also connect naturally to a broader technical SEO pillar page and related supporting articles on crawlability, XML sitemaps, canonical tags, robots directives, and site architecture.
What Is Crawling and Indexing?
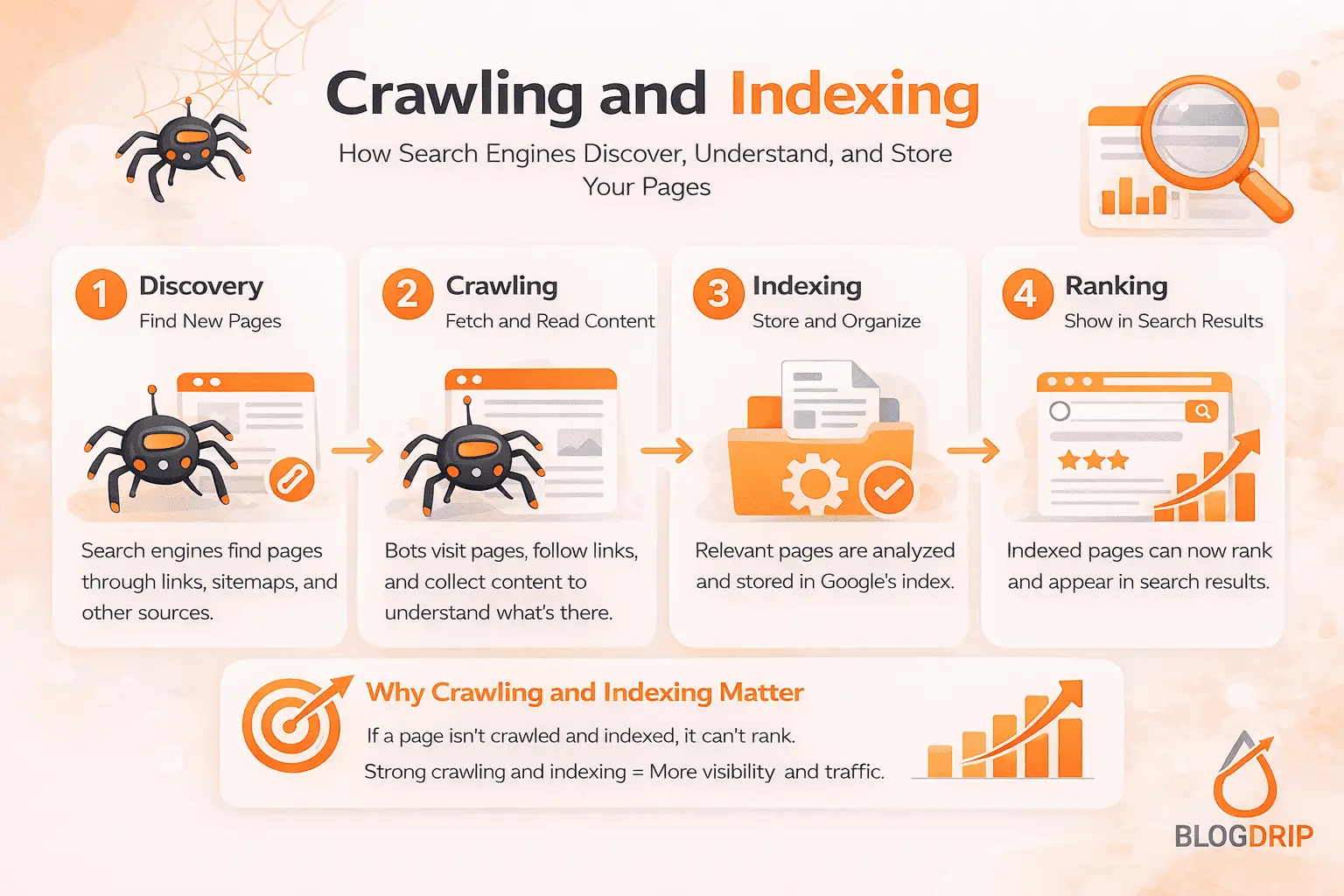
Crawling and indexing are separate stages in how search engines process the web.
Crawling is the discovery stage. Search engines follow internal links, revisit known URLs, and use sources such as XML sitemaps and backlinks to find pages and fetch their content.
Indexing is the evaluation stage. After a page is crawled, search engines decide whether it should be stored in the index and made eligible to rank in search results.
That difference matters. A page can be crawled without being indexed. It can also be technically indexable but hard to discover because it is buried in the site structure or weakly linked internally.
In practical SEO terms, crawling and indexing decide whether your content can even enter the competition.
Crawling in practical terms
When a crawler visits a page, it checks whether the page is accessible, what content it contains, which links it points to, and what technical signals it sends. Status codes, redirects, internal linking, robots instructions, and server performance all affect this stage.
Indexing in practical terms
After that, search engines decide whether the page is worth keeping in their index. This is not based on accessibility alone. It also depends on quality, uniqueness, duplication, canonical signals, and how clearly the page fits into the rest of the site.
A good SEO strategy does not aim to get every URL indexed. It aims to get the right URLs indexed.
Why Crawling and Indexing Matter
Crawling and indexing matter because they are prerequisites for visibility. Before a page can rank, it has to be found, processed, and accepted into the index.
They determine whether pages can rank at all
A page that is never discovered will not rank. A page that is discovered but not indexed will not rank either. That makes crawling and indexing foundational, not secondary.
This is also why they belong near the center of a broader technical SEO guide.
They influence crawl efficiency
Search engines do not spend unlimited attention on every site. If your website creates too many low-value URLs, duplicates, filtered combinations, or broken paths, crawlers may spend time in the wrong places.
That can delay discovery of your best pages and make the site harder to interpret. A natural supporting article here would be a cluster page on crawlability and crawl efficiency.
They affect index quality
A healthy index is a focused index. If search engines keep encountering thin, repetitive, or unnecessary pages, the site becomes less clear. Technical SEO helps direct search engines toward pages with real value and away from URLs that should not compete in search.
This connects naturally to related articles on canonical tags, meta robots, and indexation control.
How Crawling and Indexing Work
At a high level, the process can be broken into four stages: discovery, crawling, rendering, and indexation decision.
Discovery
Search engines first need to find a URL. They usually do this through internal links, XML sitemaps, backlinks, and previous crawl history.
If important pages are orphaned or too deep in the site, discovery becomes weaker. That is one reason internal linking matters so much in a pillar-and-cluster model.
Crawling
Once a page is discovered, search engines attempt to crawl it. Here they evaluate whether the page is accessible, what status code it returns, whether the redirect path is clean, and what signals the page sends.
Common issues at this stage include server errors, redirect chains, blocked resources, broken internal links, and poor URL structures.
Rendering
Many websites rely on JavaScript and dynamic page elements. Search engines can process a lot of this, but not always perfectly. If important content or navigation only appears after scripts run, the page may not be interpreted as intended.
This is where a supporting article on JavaScript SEO can fit naturally into the wider cluster.
Indexation decision
After crawling and rendering, search engines decide whether the page belongs in the index. That decision depends on technical setup, duplication signals, content quality, uniqueness, and internal support from the rest of the site.
That is an important nuance: indexing is not purely technical. Quality and purpose matter too.
Key Factors That Influence Crawling and Indexing
Several parts of a website shape how well search engines crawl and index content.
Internal Linking and Site Structure
Internal linking is one of the strongest signals in crawling and indexing. It helps search engines discover pages, understand hierarchy, and identify which content matters most.
A strong site structure makes important pages easy to reach in a small number of clicks. It also reinforces topical relationships between a pillar page and supporting cluster articles.
If a page is poorly linked or isolated, it becomes harder to discover and less clearly positioned within the site.
XML Sitemaps
XML sitemaps help search engines discover preferred URLs more efficiently. They are especially useful for important pages, new content, and updated URLs.
However, a sitemap should support your indexable content, not act as a dump of everything your CMS generates. Redirects, duplicate pages, and URLs you do not want indexed should not be there.
A useful internal link here would be a supporting page on XML sitemaps for SEO.
Robots Directives and Canonical Tags
Robots.txt controls crawler access at a broader level. Meta robots tags provide page-level indexing instructions. Canonical tags help indicate the preferred version when similar URLs exist.
These signals need to work together. If they conflict, search engines may ignore some instructions or make their own decisions instead.
That is why pages on robots.txt, meta robots directives, and canonical tags are important supporting content within the cluster.
Content Quality and Duplication
A page can be fully crawlable and still not get indexed if it offers little unique value. Thin pages, near-duplicates, weak category variations, and low-value programmatic content often struggle here.
This is where many site owners miss the bigger picture. Crawling and indexing are technical topics, but they are also influenced by content quality and differentiation.
Common Mistakes
One common mistake is assuming that every published page will eventually rank. In reality, a page must first be discovered, crawled efficiently, and judged worth indexing.
Another mistake is confusing crawling with indexing. A page appearing in a crawl report or sitemap does not mean it is indexed.
Many sites also create too many low-value URLs through filters, internal search pages, session parameters, thin archives, or duplicated category combinations. This creates crawl waste and weakens site focus.
Inconsistent technical signals are another common issue. Mixed canonicals, poor redirect handling, blocked assets, and accidental noindex rules can all create avoidable confusion.
Practical Guidance
The best way to improve crawling and indexing is to start with your priority pages.
Make sure important pages are:
- internally linked from relevant sections
- easy to reach within the site structure
- returning the correct status codes
- not blocked unintentionally
- supported by clear canonical and indexation signals
- distinct enough to deserve inclusion in the index
After that, look for crawl waste. Review duplicate URL patterns, unnecessary parameters, thin archives, broken links, and orphan pages.
It is also important to review templates and CMS behavior, not just individual URLs. Many crawling and indexing problems are systemic. They come from how the site generates, links, and manages pages at scale.
Within a pillar-and-cluster model, this page should link back to the main technical SEO pillar page and connect naturally to supporting articles on crawlability, sitemaps, canonicals, and indexation management.
Timing and Expectations
Improvements to crawling and indexing can help quickly in some cases, especially when they fix major crawl blocks, accidental noindex directives, or broken canonical logic. Other changes take longer because search engines need time to revisit pages and reassess signals.
It is also important to stay realistic. Better crawling and indexing do not guarantee rankings by themselves. They create the conditions for rankings by making sure the right pages can be found and considered.
That is why this topic should be treated as part of a broader technical SEO strategy rather than a standalone fix.
Conclusion
Crawling and indexing are essential because they determine whether search engines can find your pages, process them correctly, and include them in search results.
If these stages are weak, strong content often remains invisible. If they are handled well, your site has a much stronger foundation for growth.
As a cluster page, this article should support a broader technical SEO pillar page and link naturally to related content on crawlability, XML sitemaps, canonical tags, robots directives, and site architecture. That is the real role of crawling and indexing in a topical SEO cluster: not as a small technical detail, but as a core part of building a site that can actually perform in search.